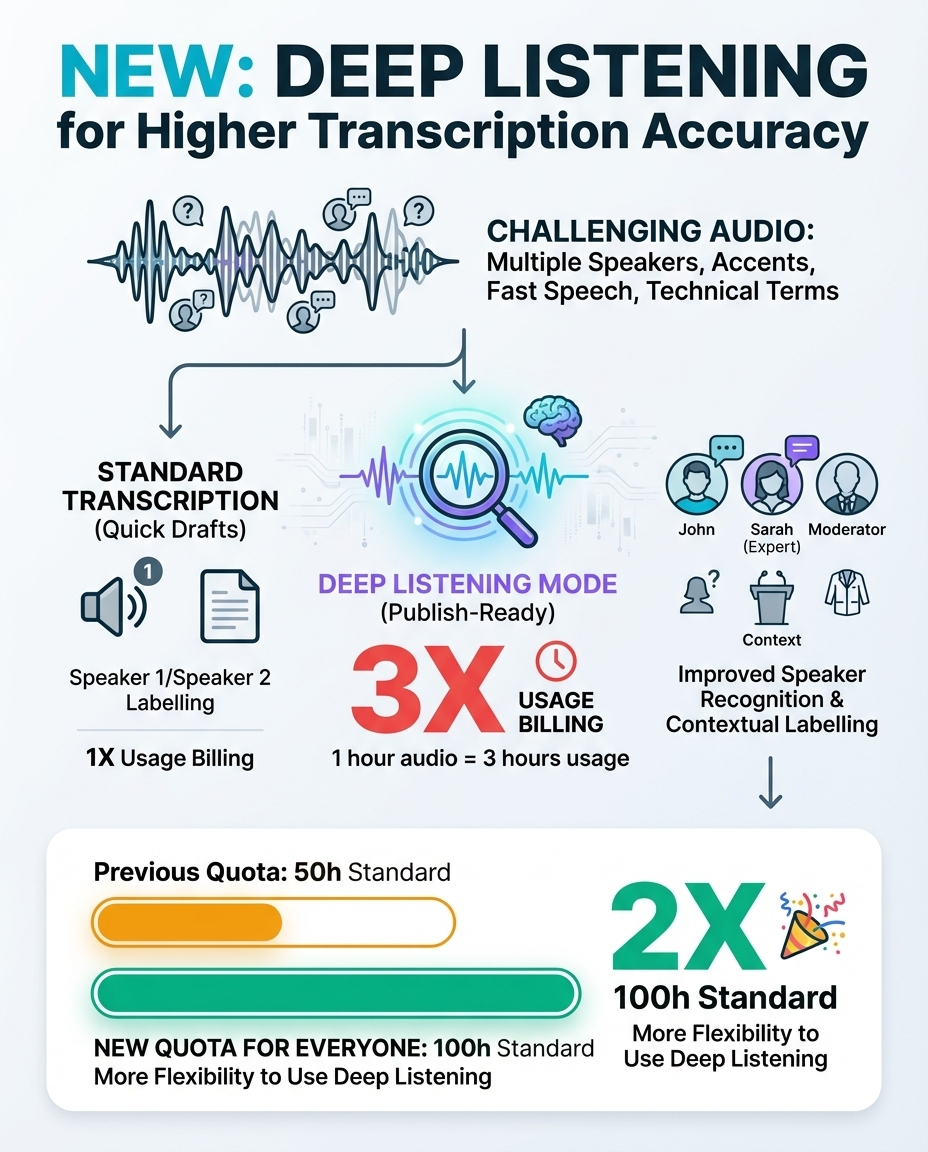
NEW IN LITTERAWORKS: Deep Listening for higher transcription accuracy
You work in various environments, with various people. This means that your recording are also varied - some are clean and simple. Others are full of background noise, overlapping speakers, strong accents, or technical language. All this makes automated transcription more difficult and can decrease the transcription precision in platforms like our Litteraworks.
We are now introducing a Deep Listening Mode.
Deep Listening is an optional transcription mode designed for higher precision. It applies a more thorough, multi-pass listening process, focusing on accuracy rather than speed. The process may take longer than the standard transcription, but the result is typically a cleaner transcript with fewer corrections needed. This mode is especially useful for interviews, meetings, panels, podcasts, and any content you plan to publish, quote, subtitle, or archive.
Our tests, based on standardized Fleurs Word-Error-Rates datasets, have shown that using Deep Listening mode, transcription accuracy increases from 96% to 98% for German language, from 90% to 95% for Greek and Serbian, and from 84% to 92% for Slovenian. We will be publishing WER comparison on our website soon.

Clearer transcripts, better speaker recognition
Besides transcription quality, One of the biggest improvements with Deep Listening is speaker recognition and labeling. Instead of relying only on standard turn-taking patterns, Deep Listening uses voice characteristics and context to keep speaker labels more consistent throughout the transcript.
In many cases, it can even recognize a person by voice and conversational context, rather than defaulting to labels like “Speaker 1” and “Speaker 2”. This makes transcripts easier to read, review, and reuse—especially in multi-speaker conversations.
Designed to be used selectively
Deep Listening is built for accuracy, so it may take longer than standard transcription. That’s intentional - we use multiple models and multi-pass to make it more precise. For everyday notes and clean audio, standard transcription is usually enough. But when accuracy truly matters, Deep Listening gives you an extra level of confidence.